Cross Validation Techniques¶
Holdout Method¶
K-fold Cross-Validation¶
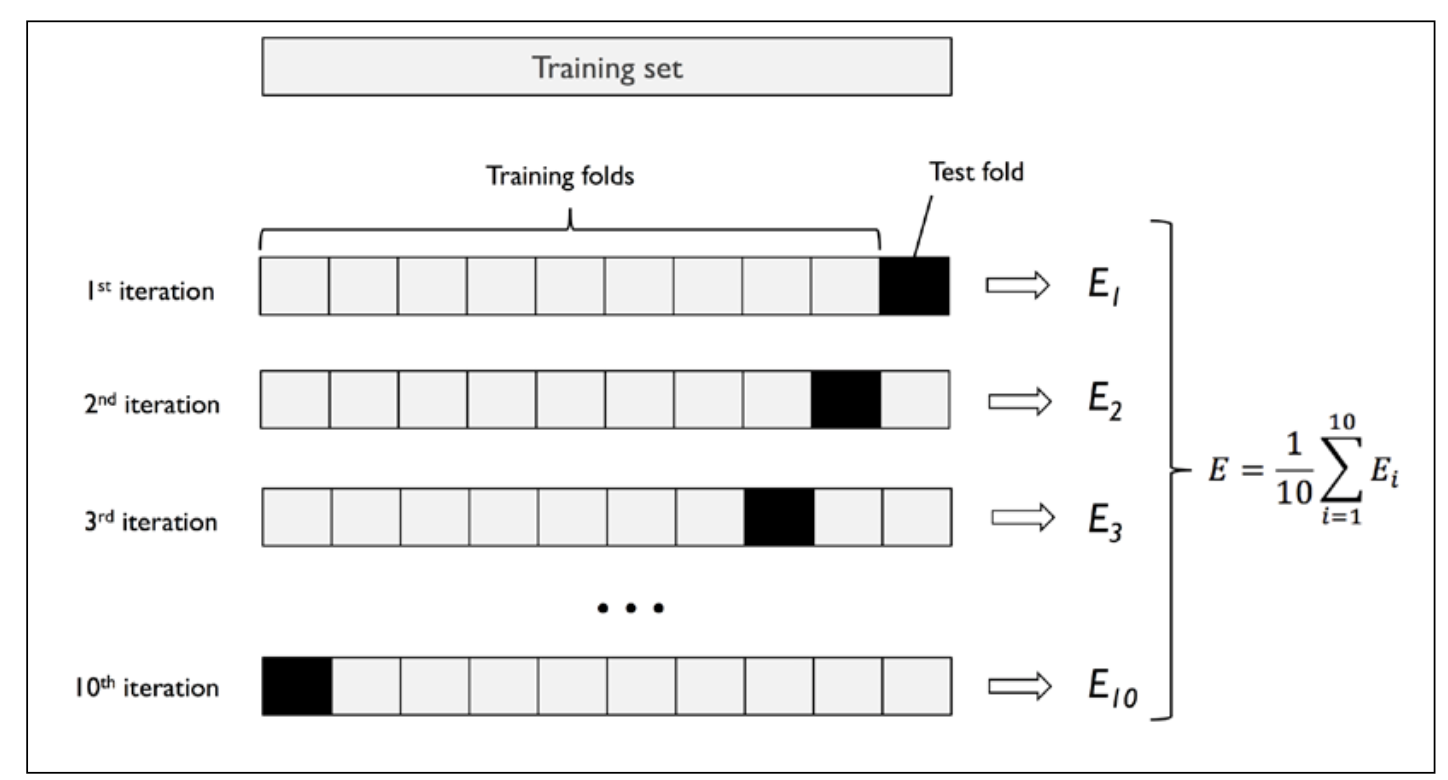
The idea is to split the training set into \(k\) folds, or splits, and with no replacement. \(k-1\) folds are used for training; one fold is used for evaluation.
-
The process is performed \(k\) times; the result is \(k\) models with \(k\) performance estimates.
-
Then, the average performance of the models is calculated. This performance estimate is less sensitive to sub-partitioning of training data.
-
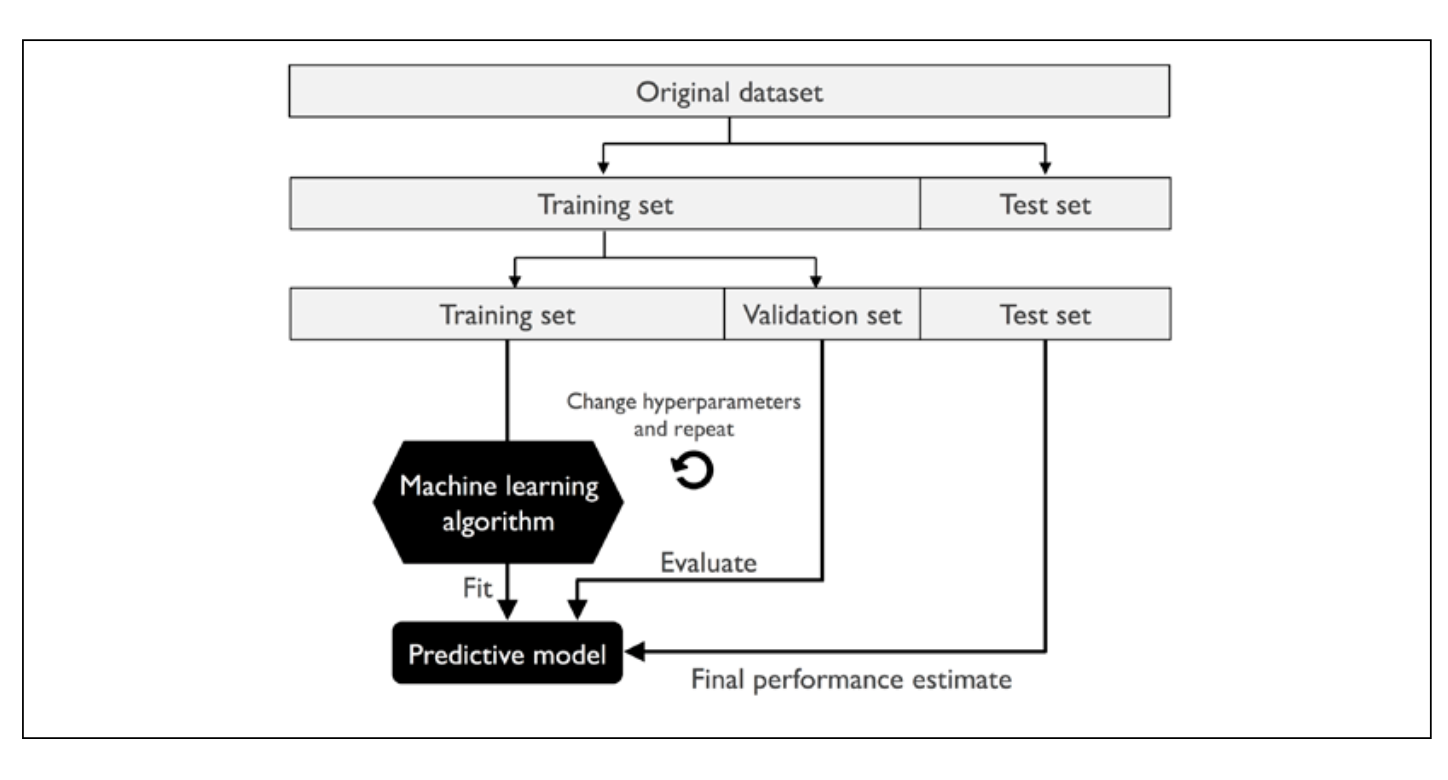
When good hyperparameter values are found, we retrain the model on the whole training dataset, yielding a final performance estimate by evaluating the independent test set.
-
One consequence of this is that each example will be used for training and validation (as a part of a test fold) exactly once. This generally yields a lower-variance estimate of model performance than the holdout method.
-
Studies have shown that k = 10 folds generally offers the best tradeoff between bias and variance.
Stratified k-Fold CV¶
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
1 2 3 4 5 6 7 8 9 10 11 12 | |
k-fold cross-validation scorer¶
- less verbose evaluation
-
Allows us to distribute the evaluation of the different folds across different CPU cores on the machine.
n_jobs = 2-> 2 cores to balance the fold scoring, for example;n_jobs = -1-> all available CPUs can be used in parallel.
1 2 3 4 5 6 7 8 9 10 11 | |
1 2 3 4 5 6 | |
Learning Curves¶
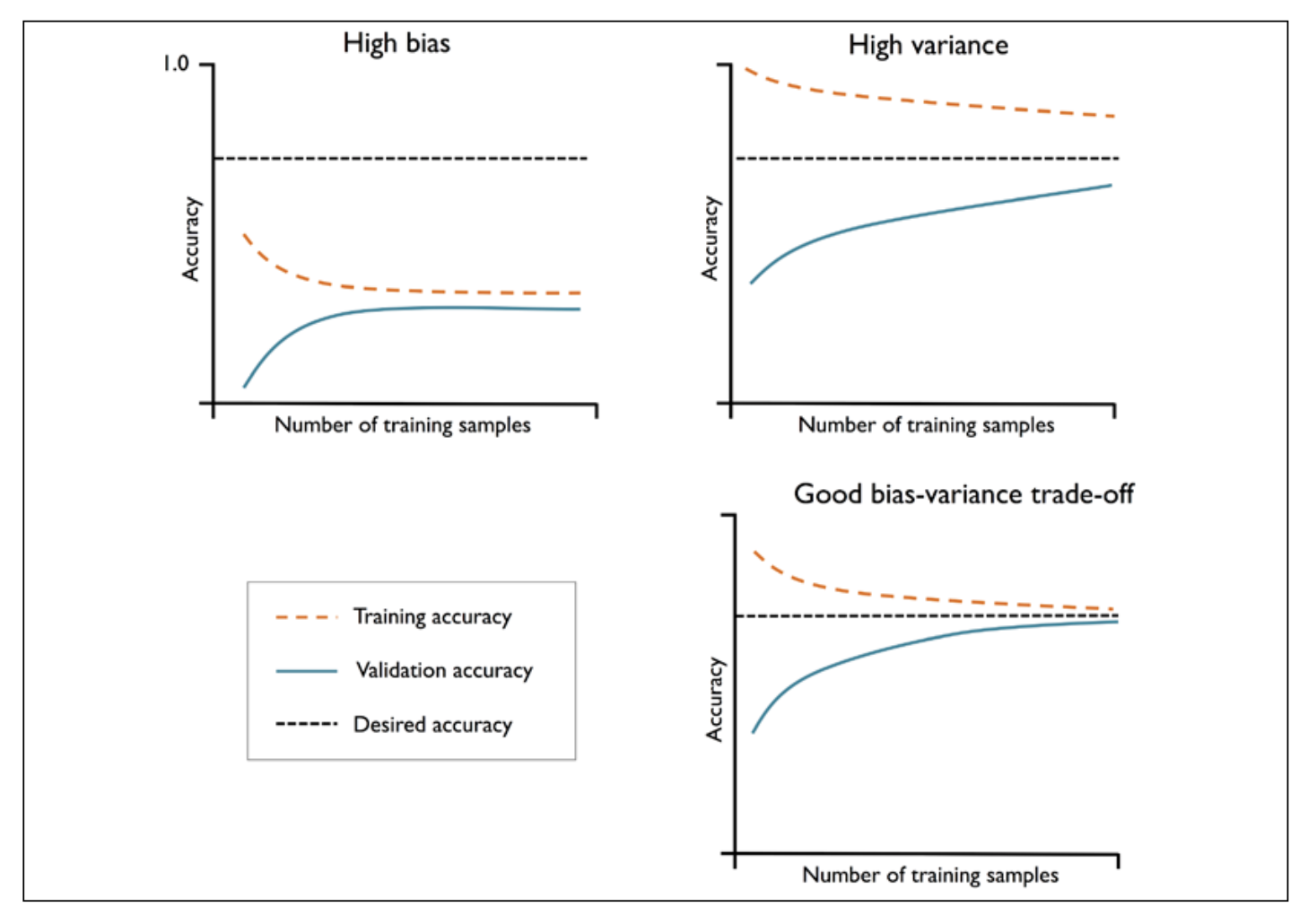
- Plot of model training and validation accuracy
| Type | Traits | Common Fixes |
|---|---|---|
| High Bias | Low training and cross-validation accuracy, underfitting | Raise number of parameters (add'l features); lower degree of regularization (SVMs), logistic regression classifiers |
| High Variance | Large gap between training and cross-validation accuracies, overfitting | Get more data, reduce model complexity, increase regularization parameter, etc. |
Validation Curves¶
- Instead of plotting training and test accuracies, validation curves vary the values of model parameters, like the inverse regularization parameter, C, in logistic regression.