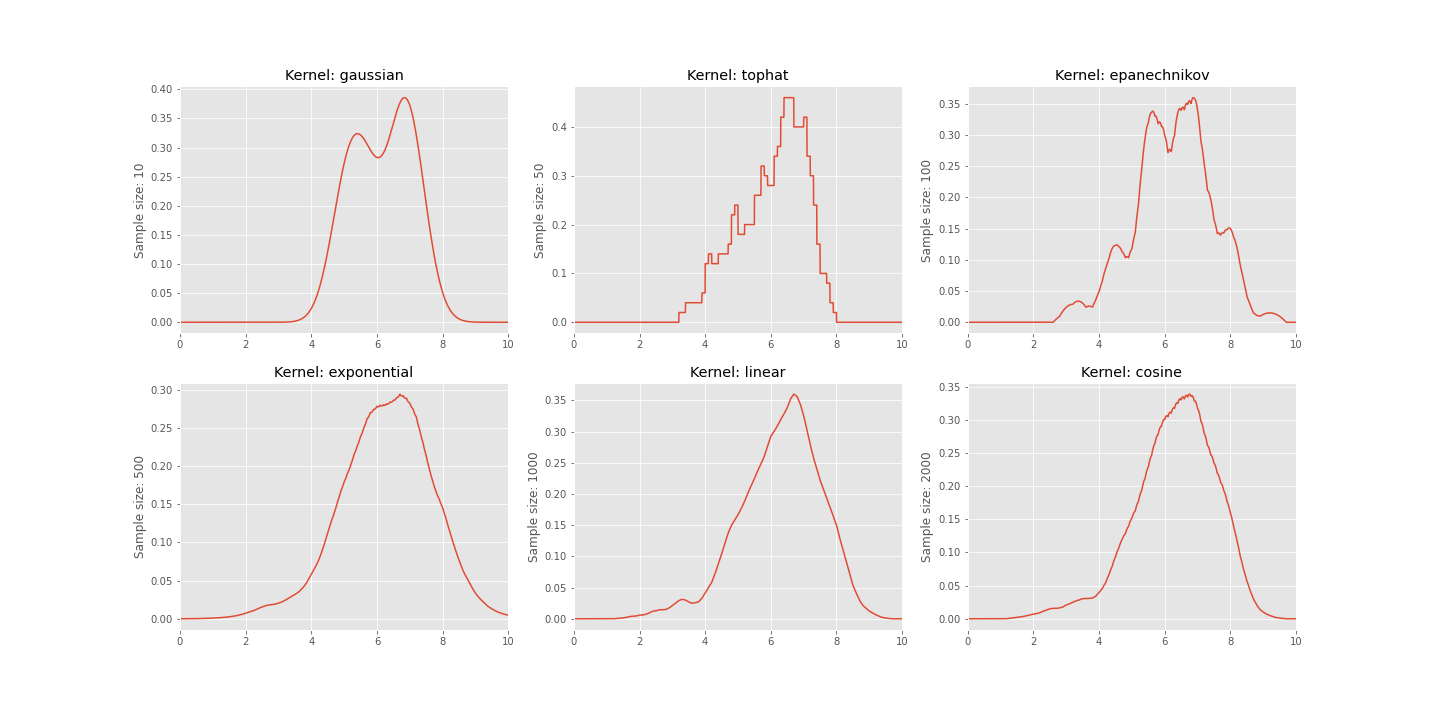
from sklearn.neighbors import KernelDensity
sample_sizes = [10, 50, 100, 500, 1000, 2000]
kernels = ['gaussian', 'tophat', 'epanechnikov',
'exponential', 'linear', 'cosine']
kdes = {sample_sizes[i]: kernels[i] for i in range(len(sample_sizes))}
plt.style.use('ggplot')
f = plt.figure(figsize=(20,10))
X_plots = np.linspace(0, 10, 2000)[:, np.newaxis]
for i, (N, K) in enumerate(kdes.items()):
s = movies['IMDB_Rating'].sample(N)
kdens = KernelDensity(kernel=K, bandwidth=0.5).fit(np.array(s).reshape(-1,1))
logdens = kdens.score_samples(X_plots)
plt.subplot(2,3,i+1)
plt.xlim(0, 10)
plt.title("Kernel: {}".format(K))
plt.ylabel("Sample size: {}".format(N))
plt.plot(X_plots[:, 0], np.exp(logdens))