Fundamentals of Data Engineering Notes¶
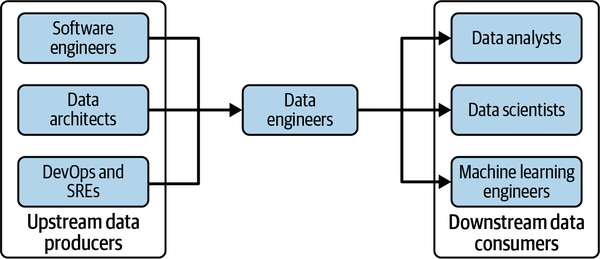
Key technical stakeholders of Data Engineering
Table of Contents¶
Data Engineering Topics¶
Companies don’t hire engineers simply to hack on code in isolation. To be worthy of their title, engineers should develop a deep understanding of the problems they’re tasked with solving, the technology tools at their disposal, and the people they work with and serve.
Engineers also need to keep an open line of communication with source system owners on changes that could break pipelines and analytics.
Storage¶
- There are many considerations when designing the storage aspects of a system.
- Is this storage solution compatible with the architecture’s required write and read speeds?
- Will storage create a bottleneck for downstream processes?
- Do you understand how this storage technology works? Are you utilizing the storage system optimally or committing unnatural acts? For instance, are you applying a high rate of random access updates in an object storage system? (This is an antipattern with significant performance overhead.)
- Will this storage system handle anticipated future scale? You should consider all capacity limits on the storage system: total available storage, read operation rate, write volume, etc.
- Will downstream users and processes be able to retrieve data in the required service-level agreement (SLA)?
- Are you capturing metadata about schema evolution, data flows, data lineage, and so forth? Metadata has a significant impact on the utility of data. Metadata represents an investment in the future, dramatically enhancing discoverability and institutional knowledge to streamline future projects and architecture changes.
- Is this a pure storage solution (object storage), or does it support complex query patterns (i.e., a cloud data warehouse)?
- Is the storage system schema-agnostic (object storage)? Flexible schema (Cassandra)? Enforced schema (a cloud data warehouse)?
- How are you tracking master data, golden records data quality, and data lineage for data governance? (We have more to say on these in “Data Management”.)
- How are you handling regulatory compliance and data sovereignty? For example, can you store your data in certain geographical locations but not others?
Data Access Frequency¶
- Patterns of retrieval vary based on the data being stored and queried.
- temperature of data
| Temperature | Frequency | Storage Type |
|---|---|---|
| Hot | up to several times a second | fast retrieval |
| lukewarm | every week or month | |
| cold | seldom queried | archival system; cheap monthly cloud storage with often pricey retrieval |
- Selection of storage will depend on a variety of factors:
- use cases
- data volume
- frequency of ingestion
- format
- size of data
Ingestion¶
Bottlenecks are often due to the source system(s) and/or the ingestion process.
Design Considerations¶
-
What are the use cases for the data I’m ingesting? Can I reuse this data rather than create multiple versions of the same dataset?
-
Are the systems generating and ingesting this data reliably, and is the data available when I need it?
-
What is the data destination after ingestion?
-
How frequently will I need to access the data?
-
In what volume will the data typically arrive?
-
What format is the data in? Can my downstream storage and transformation systems handle this format?
-
Is the source data in good shape for immediate downstream use? If so, for how long, and what may cause it to be unusable?
-
If the data is from a streaming source, does it need to be transformed before reaching its destination? Would an in-flight transformation be appropriate, where the data is transformed within the stream itself?
Stream or Batch Processing¶
-
If I ingest the data in real time, can downstream storage systems handle the rate of data flow?
-
Do I need millisecond real-time data ingestion? Or would a micro-batch approach work, accumulating and ingesting data, say, every minute?
-
What are my use cases for streaming ingestion? What specific benefits do I realize by implementing streaming? If I get data in real time, what actions can I take on that data that would be an improvement upon batch?
-
Will my streaming-first approach cost more in terms of time, money, maintenance, downtime, and opportunity cost than simply doing batch?
-
Are my streaming pipeline and system reliable and redundant if infrastructure fails?
-
What tools are most appropriate for the use case? Should I use a managed service (Amazon Kinesis, Google Cloud Pub/Sub, Google Cloud Dataflow) or stand up my own instances of Kafka, Flink, Spark, Pulsar, etc.? If I do the latter, who will manage it? What are the costs and trade-offs?
-
If I’m deploying an ML model, what benefits do I have with online predictions and possibly continuous training?
-
Am I getting data from a live production instance? If so, what’s the impact of my ingestion process on this source system?
-
Rule of Thumb: Use true real-time streaming only when a business use case is clearly identified, and that justifies the trade-offs against using batch.
Push vs. Pull¶
- ETL - commonly batch-oriented; Extract part is a query of a source snapshot.
- continuous CDC - Change Data Capture
- Event Streaming - each reading of an IOT sensor, for example, is treated as an event; simplification of software applications and data engineering.
Transformation¶
- Initial, basic transformations will map data into correct types (string to numeric, or other, etc.), put records into standard formats, remove bad ones.
- Later transformations may transform the data schema or perform normalization.
- Downstream, large-scale aggregation can be done for reporting, or featurization for ML applications.
Considerations for Transformation¶
- Cost and ROI - what is the associated business value?
- Is the transformation as simple and self-isolated as possible?
-
What business rules do the transformations support?
-
Data preparation, wrangling, and cleaning provide value for end-users of the data.
Serving Data¶
Data has value when it's used for practical purposes.
Analytics¶
- Core of most data endeavors.
Business Intelligence¶
Operational Analytics¶
Embedded Analytics¶
Machine Learning¶
- High level of data maturity is a prerequisite to using ML.
ML-specific Considerations¶
-
Is the data of sufficient quality to perform reliable feature engineering? Quality requirements and assessments are developed in close collaboration with teams consuming the data.
-
Is the data discoverable? Can data scientists and ML engineers easily find valuable data?
-
Where are the technical and organizational boundaries between data engineering and ML engineering? This organizational question has significant architectural implications.
-
Does the dataset properly represent ground truth? Is it unfairly biased?
Reverse ETL¶
- This is to feed output data (analytics, scored models, etc.) back into the source systems or SaaS platforms, in production.
Major Undercurrents Across the DE Lifecycle¶
- Security
- Access Control: Data, Systems
- Data Management
- Data governance
- Discoverability
- Definitions
- Accountability
- Data Modeling
- Data Integrity
- Data governance
- DataOps
- Data governance
- Observability, Monitoring
- Incident Reporting
- Data Architecture
- Analyze trade-offs
- Design for agility
- Add value to business
- Orchestration
- Coordinate workflows
- Schedule jobs
- Manage tasks
- Software Engineering
- Programming/coding skills
- Software design patterns
- Testing & debugging
Security¶
- Foremost consideration
- Apply the Principle of Least Privilege : grant only that access required for necessary functions today.
- Apply first to oneself;
- Only use root shell when necessary.
- Only use superuser account(s) when required to do so.
- Contribute to a culture of security.
- Apply first to oneself;
- Encryption, tokenization, data masking, obfuscation, simple, robust access controls.
- Timing
- Cloud and on-premises security administration
Data Management¶
Data management is the development, execution, and supervision of plans, policies, programs, and practices that deliver, control, protect, and enhance the value of data and information assets throughout their lifecycle.
Data management practices form a cohesive framework for all to adopt, ensuring the organization gets value from the data and handles it appropriately.
Facets of Data Management¶
Data governance¶
Discoverability¶
- End users must have quick, reliable access to data for job functions.
Metadata¶
Data about data * There are two types: auto-generated and human generated, or manual. * Interoperability and standards are challenges.
Metadata tools are only as good as their connectors to data systems and their ability to share metadata.
Categories of Metadata * Business * Business, data definitions, data rules & logic, how and where data is used, data owners; * Technical * Describes data created and used across the lifecycle. * Data model, schema, lineage, field mappings, pipeline workflows; * Operational * Info and stats on processes, job IDs, app runtime logs, errors, etc. * Reference, aka, Lookup Data * Data used to classify other data; * Internal codes, geographic codes, units of measure, internal calendars
Accountability¶
- A person assigned to a portion of data; then governs usage and activities of others.
Quality¶
"What do you get compared with what you expect?"
- Data should conform to business metadata expectations.
- The "optimization of data toward the desired state; 'What do you get compared with what you expect?'"
- Data quality testing
- Ensuring conformance to schema expectations
- Data completeness
- Precision
Master Data Management - Building consistent entity definitions called golden records.
Data modeling and design¶
- The process for converting data into a usable form is data modeling and design.
- Need to understand data modeling best practices and have the flexibility to apply appropriate levels and types of modeling to the use case.
Data lineage¶
- An audit trail of data through its lifecycle;
- A help for compliance;
- DODD, or Data Observability Driven Development;
Storage and operations¶
Data integration and interoperability¶
Data lifecycle management¶
Data systems for advanced analytics and ML¶
Ethics and privacy¶
Data Engineers need to do the right thing when no one else is watching.
- Need to mask PII (Personally Identifiable Information) and other sensitive information.
- Regulatory requirements, compliance penalties;
- Bake ethics and privacy into the data engineering lifecycle.
DataOps¶
- Best practices of Agile and SPC or, Statistical Process Control.
A data engineer must understand both the technical aspects of building software products and the business logic, quality, and metrics that will create excellent data products.
- Create a culture of best practices.
- Cycle of communication and collaboration with the business;
- Break down silos;
- Continuous learning from success and failure;
- Rapid iteration;
Three Core Elements of DataOps